数据治理之数据分片
盘古开发框架集成了数据库中间件 ShardingSphere 来提供数据治理相关功能。如:数据分片、读写分离、数据加密等。
数据分片背景
随着业务规模不断的扩大,将数据集中存储到单一节点的解决方案,在性能、可用性和运维成本等方面已经难于满足高并发和海量数据系统的场景。从性能方面来说,高并发访问请求使得集中式数据库成为系统的最大瓶颈;从可用性的方面来讲,单一数据节点或简单主从架构,已经越来越难以满足互联网 To C 业务对高可用的迫切诉求,数据库的可用性俨然已成为整个系统的关键;从运维成本和系统风险方面考虑,当一个数据库实例中的数据达到临界阈值以上,数据备份和恢复的时间成本和风险都将随着数据量的大小而愈发不可控。数据分片将存放在单一库中的数据分散至多个库或表中以达到提升性能、提高可用性和降低运维成本的效果,是应对高并发和海量数据系统的有效手段。
数据分片概念
数据分片类型
数据分片可分为垂直分片和水平分片。
垂直分片
垂直分片是按照业务域将数据库纵向切分为不同的数据库。如电商系统的用户库、订单库、会员库、仓储库、账户库等。垂直拆分可以缩库但无法缩表,即可以减小单节点下数据库数据量,但每个数据表里面的数据量是没有变化的;垂直拆分可以一定程度降低单节点数据库的负载,但是每个数据表的并发压力依旧没变。
水平分片
水平分片又称为横向拆分。相对于垂直分片,水平分片不再根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或多个表中。水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是数据分片的标准解决方案。水平分片从具体实现上又可以分为3种:只分表、只分库、分库分表。如下图所示。
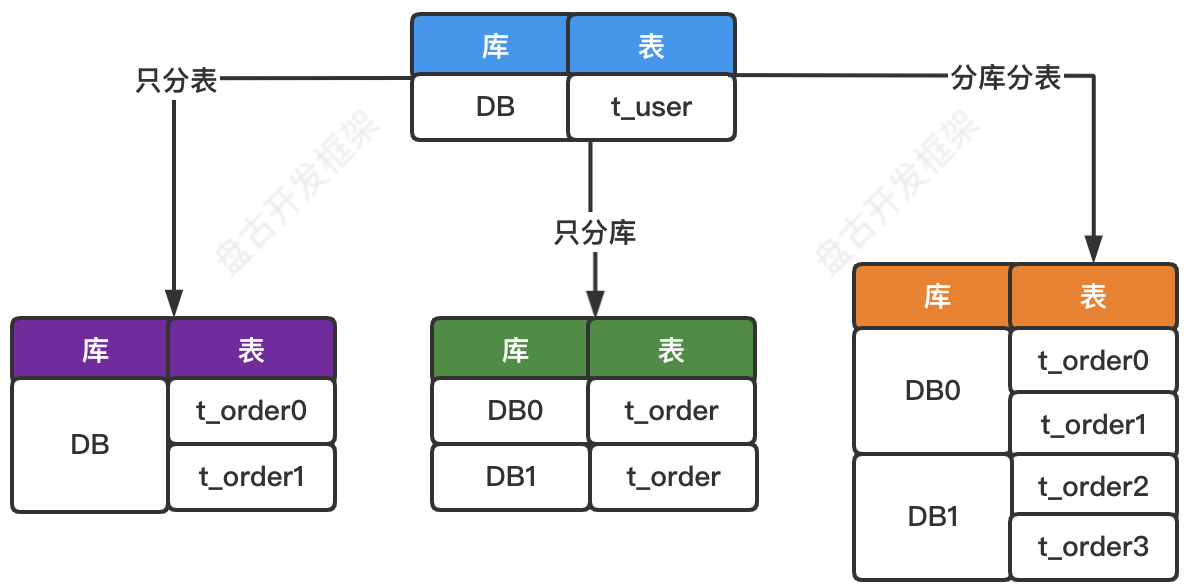
相关专业术语
- 逻辑表:相同结构的水平拆分数据库(表)的逻辑名称,是 SQL 中数据表的逻辑标识。如:t_order 表被拆分为 t_order0 和 t_order1,则 t_order 是逻辑表,并不存放数据,仅用于 SQL 中的逻辑标识。
- 真实表:在水平拆分的数据库中真实存在的物理表。如:t_order 表被拆分为 t_order0 和 t_order1,则 t_order0 和 t_order1 是真实表,用于存储数据。
- 绑定表:指分片规则一致的主表和子表。例如:t_order 表和 t_order_item 表,均按照 order_id 分片,并且使用 order_id 进行关联,则此两张表互为绑定表关系,绑定表的关联查询不会出现笛卡尔积关联或跨库关联,关联查询效率将大大提升。可以在配置中配置绑定表关系。
- 广播表:指在所有的分片数据源中都存在的表,表结构及其数据均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景。例如:字典表、地址表等。对广播表的DML操作,会自动路由到所有的数据节点。可以在配置中配置广播表。
- 单表:指不需要参与分片且所有数据源中唯一存在的表。
- 数据节点:数据分片的最小单元,由数据源名称和真实表组成。 如:ds0.t_order0。
- 分片键:用于将数据库(表)水平拆分的数据库字段。
- 分片策略:分片键 + 分片算法。
- 分布式主键:分片后的表主键不能使用数据库自身的自增列机制,需要额外引入主键生成策略。ShardingSphere 提供了基于 UUID 和 SNOWFLAKE 的分布式主键生成机制,但不建议使用。最灵活的方式还是自己生成分布式ID传给新增的实体对象。盘古框架使用 MyBatis Plus 的主键生成功能。(同样可选 UUID 主键和 SNOWFLAKE 算法主键)
提示:SNOWFLAKE 算法主键能保证递增,但不能保证数字的连续性。如果需要递增且连续的分布式主键,需要自己实现。
- 强制分片路由:基于 Hint 机制指定了强制分片路由的 SQL 请求会忽略分片逻辑,直接将请求路由至指定的真实数据节点。
数据分片面临的挑战
虽然数据分片解决了性能、可用性以及单点备份恢复等问题,但分布式的架构在获得了收益的同时,也引入了新的问题。
- 分片后的数据散乱且关系复杂,应用开发工程师和数据库管理员对数据库的操作变得异常繁重且困难。他们需要明确知道数据从哪写入,从哪读取。
- 数据分片后势必会带来分布式事务的处理。能够优雅的处理好分布式事务,这对开发而言也是一个全新的挑战。(分布式事务处理跨参考:盘古框架分布式事务最佳实践)
- 数据库请求路由至多数据节点的时候,部分SQL支持不完整或性能损耗较大的问题。
数据分片参考原则
- 需综合权衡业务场景、客观估算数据分片性价比,不要盲目分片。数据分片在获得收益的同时,也引入了新的问题。
- 分片参考临界值:一般来讲 MySQL单表记录控制在 1000 万以内、数据库单实例数据大小控制在 1 TB 以内是比较合理的范围。
- 分表不分库仅涉及本地事务,垂直分片和水平分片的分库分表均会带来分布式事务。设计过程应考虑不要人为扩大没必要的分布式事务使用边界。(也可以适当放宽)
- 分片键的规划尤为重要,需要结合业务特点来精心设计。
- 对分片表的查询必须包含分片键,且尽可能的保持单表。分片表的关联查询,请结合绑定表和广播表酌情合理使用。
总之,采用什么样的数据架构需要结合性能诉求、可用性、运维成本、开发成本、项目背景和业务场景等方面来做权衡选择。上述仅为一些孤立的参考原则。
数据分片实现原理
实现数据分片大致有 2 种方案。如下图所示。
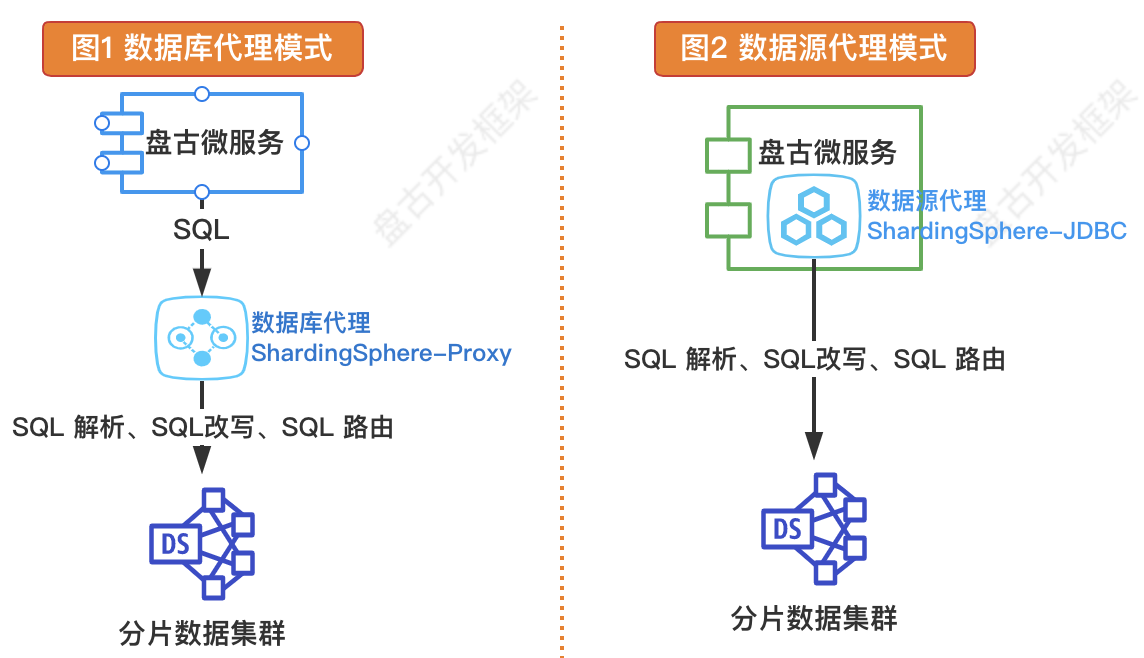
数据库代理模式(服务端代理)
在数据库和应用系统之间独立部署一个数据库代理中间件,所有的 SQL 请求先发送到这个代理,由它完成 SQL 解析、SQL改写、SQL 路由、结果集聚合等必要操作。在这种模式下,路由规则、分配逻辑都配置到代理上,数据分片的逻辑对开发人员是透明的。数据源代理模式(客户端代理)
通过在应用端引入组件包,代理应用普通数据源。在这种模式下,路由规则、分片逻辑配置到应用侧,所有 SQL 请求都通过代理数据源完成 SQL 解析、SQL改写、SQL 路由、结果集聚合等必要操作。
实现方式 | 可选组件 | 优点 | 缺点 |
|---|---|---|---|
| 数据库代理模式 | ShardingSphere-Proxy MyCat | 多语言支持 独立部署(升级简单) 对开发完全透明 | 独立部署(增加不稳定因素) 运维成本高 性能损耗高 |
| 数据源代理模式 💋 | ShardingSphere-JDBC | 集成简单、轻松驾驭 性能较好 | 嵌入 JAR(升级麻烦) 日常数据维护麻烦 |
盘古开发框架使用 ShardingSphere-JDBC 组件,通过数据源代理的方式实现数据分片功能。
安装相关盘古模块
- 盘古 Parent
- 基础模块
- JDBC 模块
- 数据治理模块
<parent>
<groupId>com.gitee.pulanos.pangu</groupId>
<artifactId>pangu-parent</artifactId>
<version>latest.version.xxx</version>
<relativePath/>
</parent>
<dependency>
<groupId>com.gitee.pulanos.pangu</groupId>
<artifactId>pangu-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>com.gitee.pulanos.pangu</groupId>
<artifactId>pangu-jdbc-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>com.gitee.pulanos.pangu</groupId>
<artifactId>pangu-data-governance-spring-boot-starter</artifactId>
</dependency>
编程实战一:只分表
初始化数据库环境
数据库表结构和分片算法逻辑如下图所示。
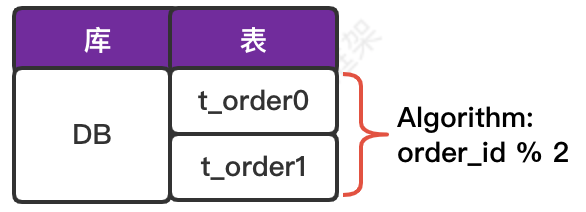
请根据如下逻辑表结构创建真实表 t_order0 和 t_order1。
create table t_order
(
order_id bigint not null primary key,
user_id int not null,
status varchar(50) null
)
comment '逻辑表:订单表';
本地配置
为便于理解,本文基于本地配置的方式编写。若改为标准的 Nacos 配置中心模式,请参阅:配置中心 章节。
spring.application.name=pangu-examples-shardingsphere-sharding
mybatis-plus.mapperLocations=classpath*:/mapper/**/*.xml
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
spring.shardingsphere.mode.type=Memory
# print shardingsphere Actual SQL log
spring.shardingsphere.props.sql-show=true
spring.shardingsphere.datasource.names=ds-0
spring.shardingsphere.datasource.ds-0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds-0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds-0.jdbc-url=jdbc:mysql://localhost:3306/pangu-examples
spring.shardingsphere.datasource.ds-0.username=root
spring.shardingsphere.datasource.ds-0.password=123456
# sharding table `t_order` configuration
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=ds-0.t_order$->{0..1}
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=order_id
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=sa-0
# sharding-algorithms configuration
spring.shardingsphere.rules.sharding.sharding-algorithms.sa-0.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.sa-0.props.algorithm-expression=t_order$->{order_id % 2}
关键配置项说明
配置项 | 配置说明 |
|---|---|
| *.t_order.actual-data-nodes | 表 t_order 对应的数据节点(真实表) |
| *.t_order.table-strategy.standard.sharding-column | 表 t_order 的分片键 |
| *.t_order.table-strategy.standard.sharding-algorithm-name | 表 t_order 的分片算法名称(自定义标识符) |
| *.sharding-algorithms.sa-0.type | 分片算法 sa-0 的类型(INLINE:内置算法) |
| *.sharding-algorithms.sa-0.props.algorithm-expression | 分片算法 sa-0 的分片表达式 |
测试用例
测试写入数据分片
写入时将分片键 order_id 对 2 求模,并根据求模结果将订单数据分片到 2 个表中存储。
@Test
public void createOrder() {
TOrderEntity entity1 = new TOrderEntity().setUserId(1).setStatus("0");
tOrderMapper.insert(entity1);
TOrderEntity entity2 = new TOrderEntity().setUserId(1).setStatus("0");
tOrderMapper.insert(entity2);
}
TOrderEntity 的 orderId 主键请通过如下注解生成。当然也可以自定义 ID 算法赋值。
@TableId(value = "order_id", type = IdType.ASSIGN_ID)
private Long orderId;
测试根据分片键路由查询
根据分片算法,将SQL查询请求路由到对应的真实表查询。
@Test
public void routingQuery() {
TOrderEntity entity = tOrderMapper.selectById(150681599250L);
log.info("结果集:{}" , entity);
TOrderEntity entity2 = tOrderMapper.selectById(150683023105L);
log.info("结果集:{}" , entity2);
}
测试结果集归并、绑定表关联查询、强制路由等特性
不再赘述。请直接获取 本范例源码 查看。
编程实战二:只分库
初始化数据库环境
数据库表结构和分片算法逻辑如下图所示。
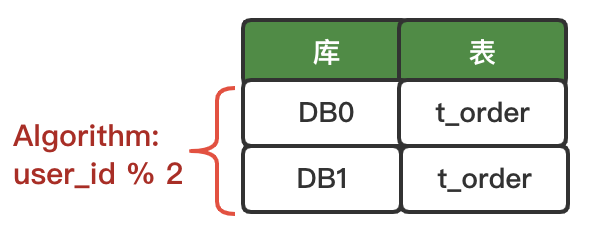
数据库逻辑表结构 同上,请自行创建相关真实库表结构。
本地配置
为便于理解,本文基于本地配置的方式编写。若改为标准的 Nacos 配置中心模式,请参阅:配置中心 章节。
spring.application.name=pangu-examples-shardingsphere-sharding
mybatis-plus.mapperLocations=classpath*:/mapper/**/*.xml
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
spring.shardingsphere.mode.type=Memory
# print shardingsphere Actual SQL log
spring.shardingsphere.props.sql-show=true
spring.shardingsphere.datasource.names=ds-0,ds-1
spring.shardingsphere.datasource.ds-0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds-0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds-0.jdbc-url=jdbc:mysql://localhost:3306/pangu-examples
spring.shardingsphere.datasource.ds-0.username=root
spring.shardingsphere.datasource.ds-0.password=123456
spring.shardingsphere.datasource.ds-1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds-1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds-1.jdbc-url=jdbc:mysql://localhost:3306/pangu-examples-1
spring.shardingsphere.datasource.ds-1.username=root
spring.shardingsphere.datasource.ds-1.password=123456
# sharding table `t_order` configuration
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=ds-$->{0..1}.t_order
spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-column=user_id
spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-algorithm-name=sa-0
# sharding-algorithms configuration
spring.shardingsphere.rules.sharding.sharding-algorithms.sa-0.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.sa-0.props.algorithm-expression=ds-$->{user_id % 2}
关键配置项说明
配置项 | 配置说明 |
|---|---|
| *.t_order.actual-data-nodes | 表 t_order 对应的数据节点(真实表) |
| *.default-database-strategy.standard.sharding-column | 表 t_order 的分片键 |
| *.default-database-strategy.standard.sharding-algorithm-name | 表 t_order 的分片算法名称(自定义标识符) |
| *.sharding-algorithms.sa-0.type | 分片算法 sa-0 的类型(INLINE:内置算法) |
| *.sharding-algorithms.sa-0.props.algorithm-expression | 分片算法 sa-0 的分片表达式 |
测试用例
测试写入数据分片
写入时将分片键:user_id 对 2 求模,根据求模结果将不同用户的订单数据分到2个库中存储。
@Test
public void createOrder() {
TOrderEntity entity1 = new TOrderEntity().setUserId(1).setStatus("0");
tOrderMapper.insert(entity1);
TOrderEntity entity2 = new TOrderEntity().setUserId(2).setStatus("0");
tOrderMapper.insert(entity2);
}
测试根据分片键路由查询
根据分片算法,将SQL查询请求路由到对应的真实表查询。
@Test
public void routingQuery() {
List<TOrderEntity> list1 = tOrderMapper.selectList(Wrappers.<TOrderEntity>lambdaQuery().eq(TOrderEntity::getUserId, 1));
log.info("结果集:{}" , list1);
List<TOrderEntity> list2 = tOrderMapper.selectList(Wrappers.<TOrderEntity>lambdaQuery().eq(TOrderEntity::getUserId, 2));
log.info("结果集:{}" , list2);
}
测试结果集归并、绑定表关联查询、强制路由等特性
不再赘述。请直接获取 本范例源码 查看。
编程实战三:分库分表
初始化数据库环境
数据库表结构和分片算法逻辑如下图所示。
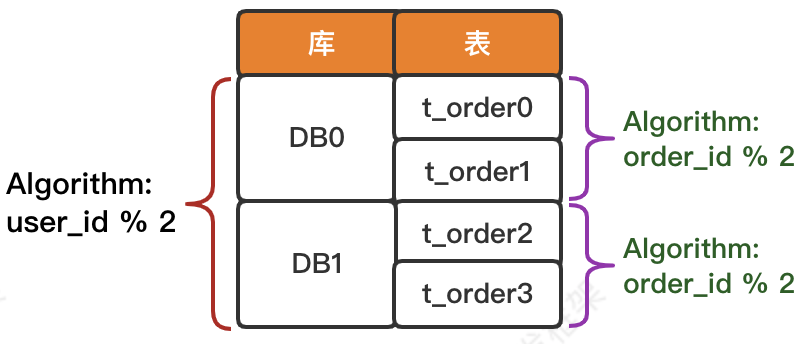
数据库逻辑表结构 同上,请自行创建相关真实库表结构。
本地配置
为便于理解,本文基于本地配置的方式编写。若改为标准的 Nacos 配置中心模式,请参阅:配置中心 章节。
spring.application.name=pangu-examples-shardingsphere-sharding
mybatis-plus.mapperLocations=classpath*:/mapper/**/*.xml
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
spring.shardingsphere.mode.type=Memory
# print shardingsphere Actual SQL log
spring.shardingsphere.props.sql-show=true
spring.shardingsphere.datasource.names=ds-0,ds-1
spring.shardingsphere.datasource.ds-0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds-0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds-0.jdbc-url=jdbc:mysql://localhost:3306/pangu-examples
spring.shardingsphere.datasource.ds-0.username=root
spring.shardingsphere.datasource.ds-0.password=123456
spring.shardingsphere.datasource.ds-1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds-1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds-1.jdbc-url=jdbc:mysql://localhost:3306/pangu-examples-1
spring.shardingsphere.datasource.ds-1.username=root
spring.shardingsphere.datasource.ds-1.password=123456
# sharding table `t_order` configuration
spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-column=user_id
spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-algorithm-name=sa-0
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=ds-$->{0..1}.t_order$->{0..1}
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=order_id
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=sa-1
# sharding databases algorithms configuration
spring.shardingsphere.rules.sharding.sharding-algorithms.sa-0.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.sa-0.props.algorithm-expression=ds-$->{user_id % 2}
# sharding tables algorithms configuration
spring.shardingsphere.rules.sharding.sharding-algorithms.sa-1.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.sa-1.props.algorithm-expression=t_order$->{order_id % 2}
关键配置项说明
配置项 | 配置说明 |
|---|---|
| *.t_order.actual-data-nodes | 表 t_order 对应的数据节点(真实表) |
| *.default-database-strategy.standard.sharding-column | 表 t_order 的分库分片键 |
| *.default-database-strategy.standard.sharding-algorithm-name | 表 t_order 的分库分片算法名称 |
| *.t_order.table-strategy.standard.sharding-column | 表 t_order 的库内分表分片键 |
| *.t_order.table-strategy.standard.sharding-algorithm-name | 表 t_order 的库内分表算法名称 |
| *.sharding-algorithms.sa-0.type | 分库算法的类型 |
| *.sharding-algorithms.sa-0.props.algorithm-expression | 分库表达式 |
| *.sharding-algorithms.sa-1.type | 库内分表算法的类型 |
| *.sharding-algorithms.sa-1.props.algorithm-expression | 库内分表表达式 |
测试用例
测试写入数据分片
写入时将分片键 user_id 对 2 求模,根据求模结果将订单数据分片到 2 个库中,再将分片键 order_id 对 2 求模,并根据求模结果将订单数据分片到库中不同的表来存储。(注意:本例有两个分片键,第一个用来分库;第二个用来库内分表。)
@Test
public void createOrder() {
TOrderEntity entity1 = new TOrderEntity().setUserId(1).setStatus("0");
tOrderMapper.insert(entity1);
TOrderEntity entity2 = new TOrderEntity().setUserId(2).setStatus("0");
tOrderMapper.insert(entity2);
}
TOrderEntity 的 orderId 主键请通过如下注解生成。当然也可以自定义 ID 算法赋值。
@TableId(value = "order_id", type = IdType.ASSIGN_ID)
private Long orderId;
测试根据分片键路由查询
根据分片算法,将SQL查询请求路由到对应的真实表查询。
@Test
public void routingQuery() {
List<TOrderEntity> list1 = tOrderMapper.selectList(Wrappers.<TOrderEntity>lambdaQuery().eq(TOrderEntity::getUserId, 1));
log.info("结果集:{}" , list1);
List<TOrderEntity> list2 = tOrderMapper.selectList(Wrappers.<TOrderEntity>lambdaQuery().eq(TOrderEntity::getUserId, 2));
log.info("结果集:{}" , list2);
}
测试结果集归并、绑定表关联查询、强制路由等特性
不再赘述。请直接获取 本范例源码 查看。
- 对分片表的查询操作,查询条件务必要包含分片键,否则会遍历所有数据节点。尽量维持单表查询。
- 如果需要关联查询,请结合绑定表、广播表酌情合理应用。
本文相关范例源码
- pangu-examples-shardingsphere-sharding:数据治理之数据分片范例
下一步
继续阅读其它章节获取你想要的答案或通过我们的 开发者社区 寻求更多帮助。