
AIGC 特别标注: 本文内容由大语言模型自动生成或人工演绎。
当下大语言模型如火如荼,我也很好奇。所以,今天我以「大数据分析生态有哪些技术栈」为题,简单体验了一下如下 3 个大语言模型。具体效果大家自己看吧。
- 百度 文心一言 (中国互联网访问)
- Google Bard (国际互联网访问)
- OpenAI ChatGPT 3.5 (国际互联网访问)
此场景答题效果,个人感觉 Google Bard 优于 OpenAI ChatGPT 3.5 优于 百度文心一言。
大语言模型生成内容
百度 文心一言
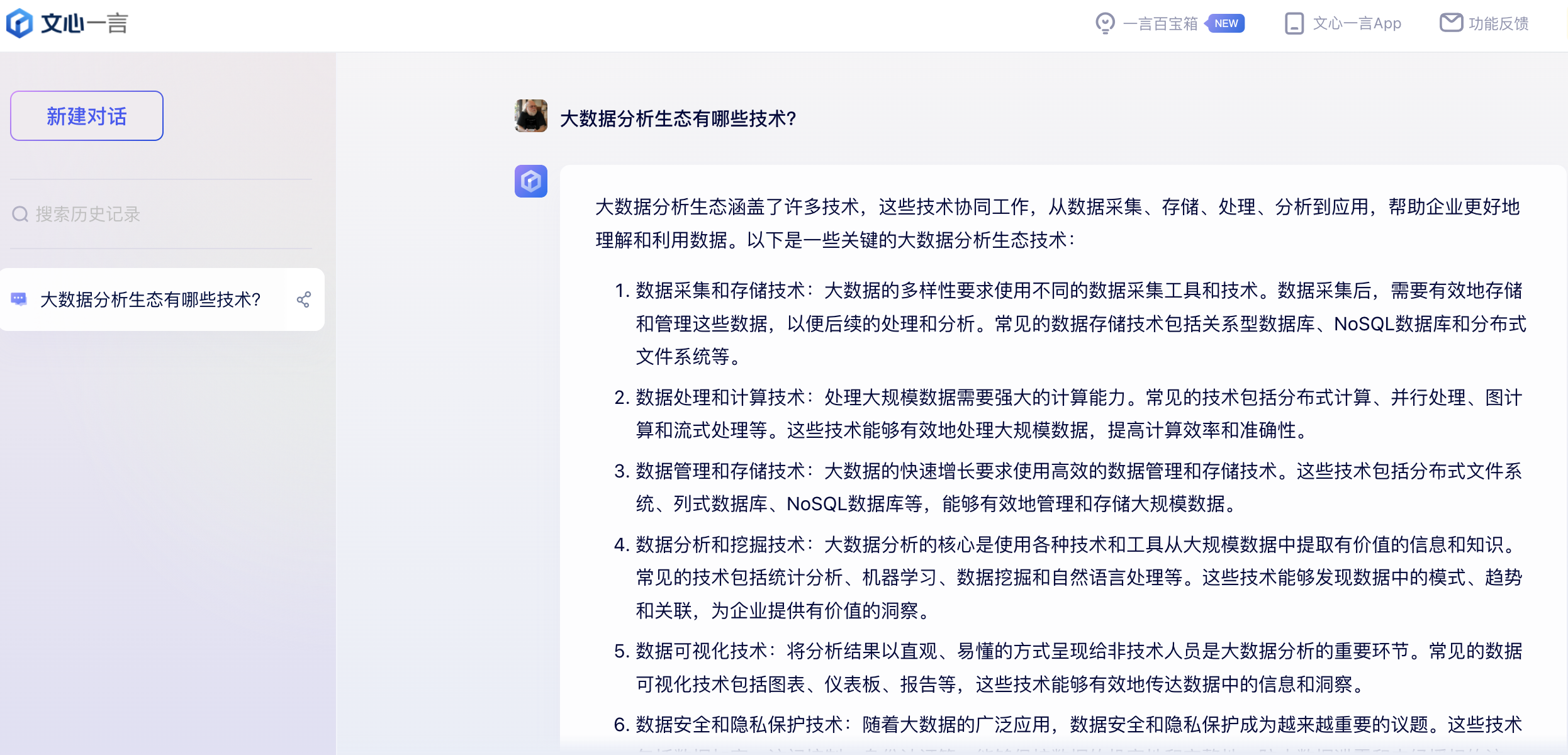
大数据分析生态涵盖了许多技术,这些技术协同工作,从数据采集、存储、处理、分析到应用,帮助企业更好地理解和利用数据。以下是一些关键的大数据分析生态技术.
数据采集和存储技术
大数据的多样性要求使用不同的数据采集工具和技术。数据采集后,需要有效地存储和管理这些数据,以便后续的处理和分析。常见的数据存储技术包括关系型数据库、NoSQL数据库和分布式文件系统等。
数据处理和计算技术
处理大规模数据需要强大的计算能力。常见的技术包括分布式计算、并行处理、图计算和流式处理等。这些技术能够有效地处理大规模数据,提高计算效率和准确性。
数据管理和存储技术
大数据的快速增长要求使用高效的数据管理和存储技术。这些技术包括分布式文件系统、列式数据库、NoSQL数据库等,能够有效地管理和存储大规模数据。
数据分析和挖掘技术
大数据分析的核心是使用各种技术和工具从大规模数据中提取有价值的信息和知识。常见的技术包括统计分析、机器学习、数据挖掘和自然语言处理等。这些技术能够发现数据中的模式、趋势和关联,为企业提供有价值的洞察。
数据可视化技术
将分析结果以直观、易懂的方式呈现给非技术人员是大数据分析的重要环节。常见的数据可视化技术包括图表、仪表板、报告等,这些技术能够有效地传达数据中的信息和洞察。
数据安全和隐私保护技术
随着大数据的广泛应用,数据安全和隐私保护成为越来越重要的议题。这些技术包括数据加密、访问控制、身份认证等,能够保护数据的机密性和完整性,防止数据泄露和未经授权的访问。
数据集成和整合技术
大数据的多样性和复杂性要求将来自不同来源和平台的数据集成和整合在一起。这些技术包括数据抽取、转换、加载(ETL)、数据联邦等,能够将分散的数据整合到一个统一的数据仓库或数据湖中,方便后续的分析和处理。
综上所述,大数据分析生态涵盖了多个领域和技术,这些技术协同工作,帮助企业更好地利用数据。了解和掌握这些技术是进行大数据分析和应用的关键。
Google Bard
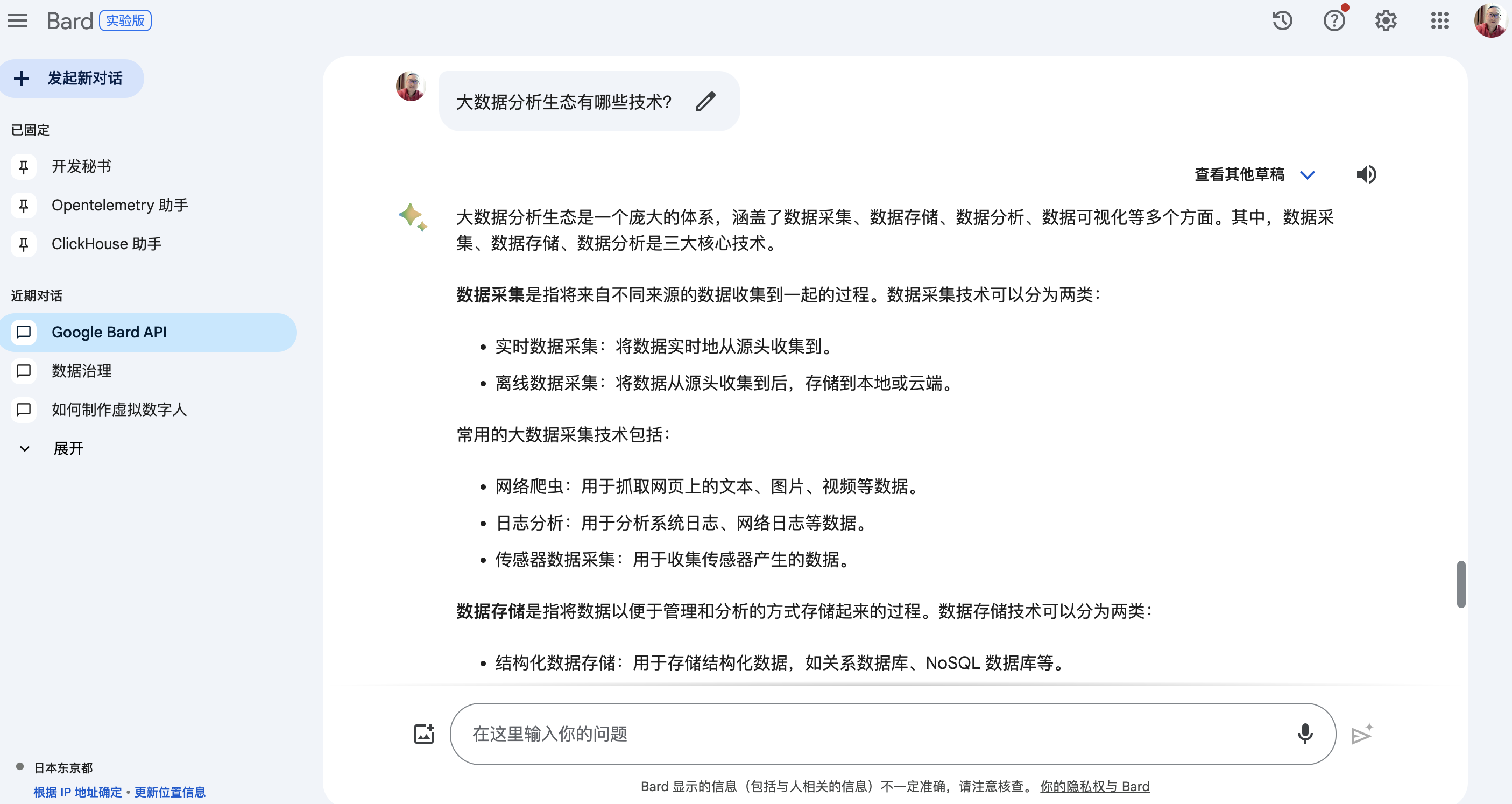
大数据分析生态是一个庞大的体系,涵盖了数据采集、数据存储、数据分析、数据可视化等多个方面。其中,数据采集、数据存储、数据分析是三大核心技术。
数据采集 是指将来自不同来源的数据收集到一起的过程。数据采集技术可以分为两类:
- 实时数据采集:将数据实时地从源头收集到。
- 离线数据采集:将数据从源头收集到后,存储到本地或云端。
常用的大数据采集技术包括:
- 网络爬虫:用于抓取网页上的文本、图片、视频等数据。
- 日志分析:用于分析系统日志、网络日志等数据。
- 传感器数据采集:用于收集传感器产生的数据。
数据存储 是指将数据以便于管理和分析的方式存储起来的过程。数据存储技术可以分为两类:
- 结构化数据存储:用于存储结构化数据,如关系数据库、NoSQL 数据库等。
- 非结构化数据存储:用于存储非结构化数据,如文本、图片、视频等。
常用的大数据存储技术包括:
- 关系数据库:用于存储结构化数据,如业务数据、用户数据等。
- NoSQL 数据库:用于存储非结构化数据,如日志数据、图片数据等。
- 分布式文件系统:用于存储大规模的文件数据,如图像、视频等。
数据分析 是指对数据进行分析,以发现其中的规律和趋势的过程。数据分析技术可以分为两类:
- 传统数据分析:使用传统的统计方法进行数据分析。
- 机器学习:使用机器学习算法进行数据分析。
常用的大数据分析技术包括:
- 统计分析:用于对数据进行统计分析,如平均值、方差、标准差等。
- 机器学习:用于对数据进行机器学习分析,如分类、回归、聚类等。
数据可视化 是指将数据以图表、图形等方式呈现的过程。数据可视化可以帮助人们更直观地理解数据。
常用的数据可视化技术包括:
- 图表:用于展示数据的趋势和分布。
- 图形:用于展示数据之间的关系。
- 地图:用于展示数据的地理分布。
除了上述三大核心技术外,大数据分析生态还包括以下技术:
数据管理:用于管理数据的生命周期,如数据采集、存储、分析、应用等。
数据治理:用于确保数据的质量和安全。
数据安全:用于保护数据免受攻击。
大数据分析生态是一个不断发展的体系,随着技术的不断进步,新的技术也将不断涌现。
OpenAI ChatGPT 3.5
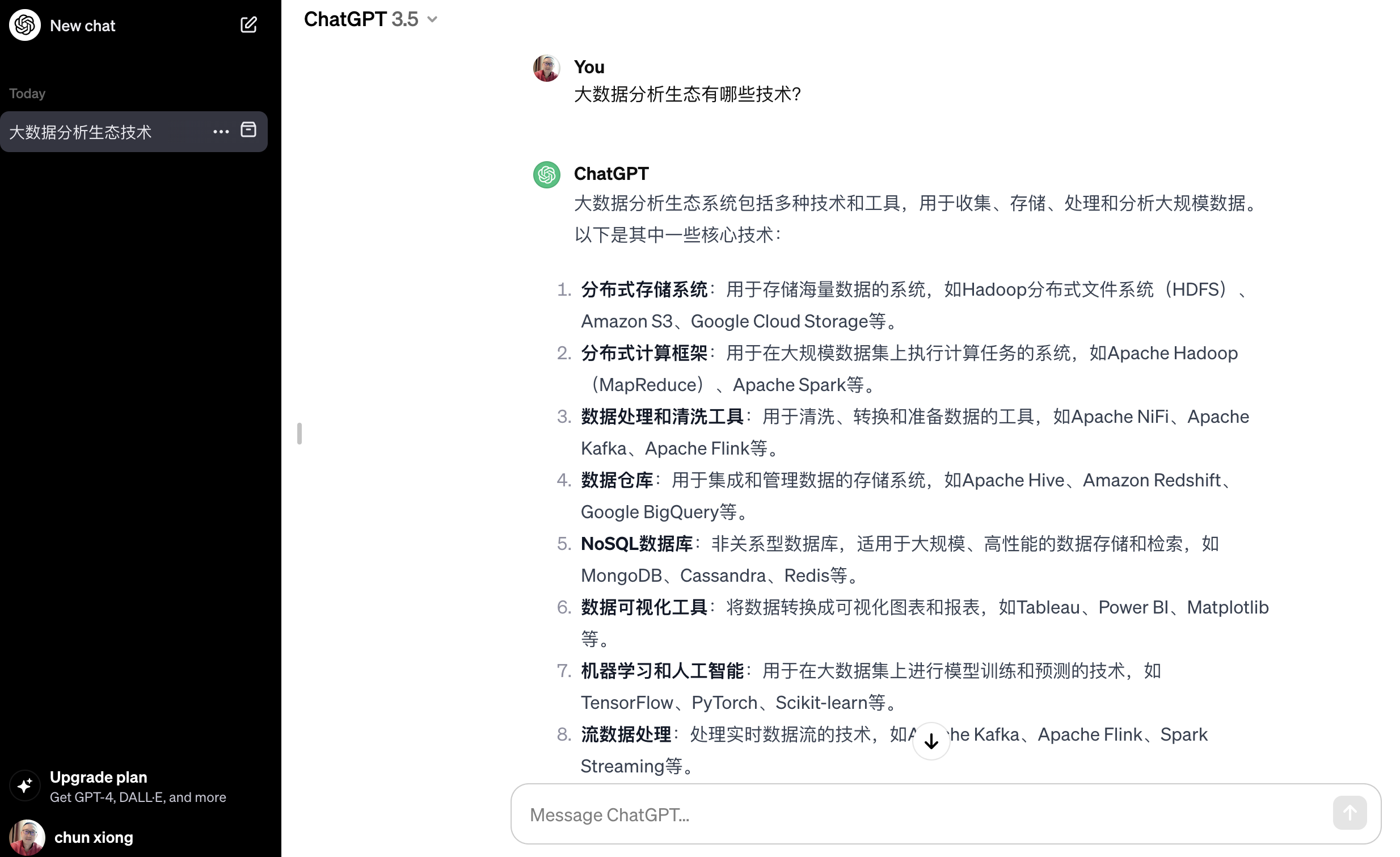
大数据分析生态系统包括多种技术和工具,用于收集、存储、处理和分析大规模数据。以下是其中一些核心技术。
分布式存储系统:用于存储海量数据的系统,如Hadoop分布式文件系统(HDFS)、Amazon S3、Google Cloud Storage 等。
分布式计算框架:用于在大规模数据集上执行计算任务的系统,如 Apache Hadoop(MapReduce)、Apache Spark 等。
数据处理和清洗工具:用于清洗、转换和准备数据的工具,如Apache NiFi、Apache Kafka、Apache Flink 等。
数据仓库:用于集成和管理数据的存储系统,如 Apache Hive、Amazon Redshift、Google BigQuery 等。
NoSQL 数据库:非关系型数据库,适用于大规模、高性能的数据存储和检索,如 MongoDB、Cassandra、Redis 等。
数据可视化工具:将数据转换成可视化图表和报表,如 Tableau、Power BI、Matplotlib 等。
机器学习和人工智能:用于在大数据集上进行模型训练和预测的技术,如 TensorFlow、PyTorch、Scikit-learn 等。
流数据处理:处理实时数据流的技术,如 Apache Kafka、Apache Flink、Spark Streaming 等。
容器化和编排技术:用于构建、部署和管理大数据应用程序的容器化环境,如 Docker、Kubernetes 等。
这些技术共同构成了大数据分析生态系统,为企业和组织提供了处理和分析大规模数据的能力,帮助他们从数据中获得洞见和价值。